OLAP技術(shù)選型 數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)的核心考量
OLAP技術(shù)選型:數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)的核心考量
在構(gòu)建在線分析處理(OLAP)系統(tǒng)時(shí),技術(shù)選型是決定項(xiàng)目成敗的關(guān)鍵環(huán)節(jié)。其核心并非選擇一個(gè)“萬能”的技術(shù),而是根據(jù)具體的業(yè)務(wù)需求、數(shù)據(jù)特征和運(yùn)維環(huán)境,為 數(shù)據(jù)處理 和 存儲(chǔ)支持服務(wù) 這兩個(gè)核心支柱,匹配合適的技術(shù)棧。
一、 對(duì)什么進(jìn)行選型?—— 明確選型對(duì)象
OLAP技術(shù)選型主要圍繞以下四個(gè)層面展開:
- 計(jì)算引擎(數(shù)據(jù)處理的核心):負(fù)責(zé)執(zhí)行復(fù)雜的多維分析查詢。選型需評(píng)估其:
- 查詢性能:對(duì)即席查詢(Ad-hoc)、多表關(guān)聯(lián)、復(fù)雜聚合的響應(yīng)速度。
- 并發(fā)能力:支持的同時(shí)在線分析用戶數(shù)。
- SQL兼容性與擴(kuò)展性:對(duì)標(biāo)準(zhǔn)SQL的支持度,以及是否提供高級(jí)分析函數(shù)(如窗口函數(shù))。
- 計(jì)算模型:基于MPP(大規(guī)模并行處理)、預(yù)計(jì)算(如Cube)還是向量化執(zhí)行引擎。
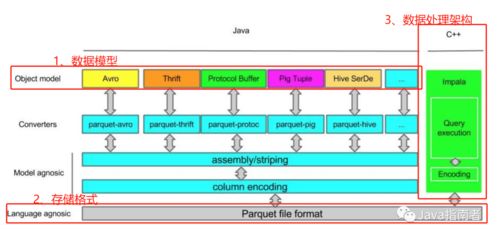
- 存儲(chǔ)格式與數(shù)據(jù)庫(數(shù)據(jù)的載體):決定了數(shù)據(jù)的組織、壓縮和讀取效率。選型需關(guān)注:
- 列式存儲(chǔ):如Parquet、ORC,適合OLAP場(chǎng)景,可高效壓縮和快速掃描特定列。
- 索引技術(shù):如位圖索引、稀疏索引、跳表等,加速數(shù)據(jù)定位。
- 數(shù)據(jù)分區(qū)與分片:支持按時(shí)間、地域等維度的分區(qū)策略,優(yōu)化查詢性能和數(shù)據(jù)管理。
- 架構(gòu)模式(系統(tǒng)的骨架):決定了系統(tǒng)的擴(kuò)展性、成本與靈活性。
- 一體化架構(gòu):計(jì)算與存儲(chǔ)緊耦合(如ClickHouse、Doris)。優(yōu)勢(shì)是部署簡(jiǎn)單、極致性能;劣勢(shì)是存儲(chǔ)計(jì)算無法獨(dú)立擴(kuò)展,資源利用率可能不足。
- 存算分離架構(gòu):計(jì)算層與存儲(chǔ)層解耦(如Presto/Trino on HDFS/S3, StarRocks on 對(duì)象存儲(chǔ))。優(yōu)勢(shì)是資源彈性伸縮、成本優(yōu)化、易于共享數(shù)據(jù);劣勢(shì)是網(wǎng)絡(luò)延遲可能影響性能。
- 支持服務(wù)與生態(tài)系統(tǒng)(系統(tǒng)的血脈):確保系統(tǒng)可運(yùn)維、可管理、易集成。
- 數(shù)據(jù)導(dǎo)入/導(dǎo)出:是否支持批量(Batch)、實(shí)時(shí)流式(Streaming)數(shù)據(jù)接入,以及與Kafka、Flink、DataX等工具的集成度。
- 元數(shù)據(jù)管理與數(shù)據(jù)治理:是否有完善的Catalog管理、權(quán)限控制、數(shù)據(jù)血緣和行級(jí)安全功能。
- 監(jiān)控與運(yùn)維:提供的監(jiān)控指標(biāo)是否豐富(QPS、查詢延遲、資源使用率),運(yùn)維工具是否完備。
- 云服務(wù)與托管服務(wù):是否提供成熟的云托管版本(如AWS Redshift、Google BigQuery、阿里云AnalyticDB),以降低運(yùn)維復(fù)雜度。
二、 數(shù)據(jù)處理選型的核心維度
數(shù)據(jù)處理能力的選型,本質(zhì)上是為 “計(jì)算” 尋找最優(yōu)解:
- 場(chǎng)景驅(qū)動(dòng):
- 高并發(fā)、低延遲的交互式查詢:可考慮ClickHouse、Doris/StarRocks。
- 超大規(guī)模數(shù)據(jù)集上的復(fù)雜即席查詢:可考慮Presto/Trino、Impala(存算分離架構(gòu))。
- 預(yù)計(jì)算模式固定的報(bào)表分析:可考慮Apache Kylin。
- 數(shù)據(jù)規(guī)模與更新模式:
- 海量歷史數(shù)據(jù)+高頻實(shí)時(shí)更新:需要引擎支持高效的 Upsert 或 Merge-on-Read 能力(如StarRocks的主鍵模型)。
- 僅追加(Append-only)的日志數(shù)據(jù):則對(duì)更新能力要求不高。
- 成本與性能平衡:追求極致查詢速度,可能選擇一體化架構(gòu);追求資源利用率和彈性,則存算分離架構(gòu)更優(yōu)。
三、 存儲(chǔ)支持服務(wù)選型的核心維度
存儲(chǔ)支持服務(wù)的選型,是為 “數(shù)據(jù)” 的持久化、管理與訪問提供保障:
- 存儲(chǔ)成本與性能:
- 本地SSD/HDD:性能最高,但成本高、擴(kuò)展性差。
- 對(duì)象存儲(chǔ)(如S3、OSS):成本極低、容量無限、持久性高,但延遲較高。需搭配緩存層或選擇對(duì)其有深度優(yōu)化的查詢引擎(如StarRocks)。
- 數(shù)據(jù)湖與數(shù)據(jù)倉庫的融合:
- 是否需要直接查詢數(shù)據(jù)湖(如HDFS、S3)上的原始格式(Parquet/ORC)數(shù)據(jù)?這需要引擎具備強(qiáng)大的 湖倉一體 或 聯(lián)邦查詢 能力(如Trino、Apache Hudi/Iceberg集成)。
- 服務(wù)可用性與可運(yùn)維性:
- 是否選擇全托管云服務(wù),以換取更高的可用性(SLA)和更少的運(yùn)維投入?這需要評(píng)估云供應(yīng)商綁定風(fēng)險(xiǎn)與長期成本。
四、 如何進(jìn)行選型決策
一個(gè)明智的OLAP技術(shù)選型,應(yīng)遵循以下路徑:
- 定義需求:明確數(shù)據(jù)量級(jí)(TB/PB?)、查詢模式(簡(jiǎn)單聚合/復(fù)雜關(guān)聯(lián)?)、并發(fā)用戶數(shù)、實(shí)時(shí)性要求(分鐘級(jí)/秒級(jí)?)和預(yù)算成本。
- 評(píng)估技術(shù)矩陣:將上述需求映射到各候選技術(shù)(如ClickHouse, Doris/StarRocks, Presto/Trino, 云數(shù)倉等)在計(jì)算、存儲(chǔ)、架構(gòu)、服務(wù)四個(gè)維度的能力象限中。
- 概念驗(yàn)證:使用真實(shí)業(yè)務(wù)查詢和數(shù)據(jù)集樣本,對(duì)2-3個(gè)最優(yōu)候選進(jìn)行性能、功能和穩(wěn)定性測(cè)試。
- 綜合權(quán)衡:在性能、成本、復(fù)雜度、團(tuán)隊(duì)技能和未來擴(kuò)展性之間做出最終權(quán)衡。
沒有“銀彈”技術(shù),只有最適合當(dāng)前場(chǎng)景的技術(shù)組合。成功的OLAP系統(tǒng)選型,必然是數(shù)據(jù)處理能力與存儲(chǔ)支持服務(wù)兩者協(xié)同設(shè)計(jì)、共同優(yōu)化的結(jié)果。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.germanyfanyi.com/product/57.html
更新時(shí)間:2026-05-18 10:25:12